This tutorial shows how to implement a bidirectional LSTM-CNN deep neural network, for the task of named entity recognition, in Apache MXNet. The architecture is based on the model submitted by Jason Chiu and Eric Nichols in their paper Named Entity Recognition with Bidirectional LSTM-CNNs. Their model achieved state of the art performance on CoNLL-2003 and OntoNotes public datasets with minimal feature generation.
What is Named Entity Recognition?
Named entity recogniton (NER) refers to the task of classifying entities in text. It’s best explained by example:
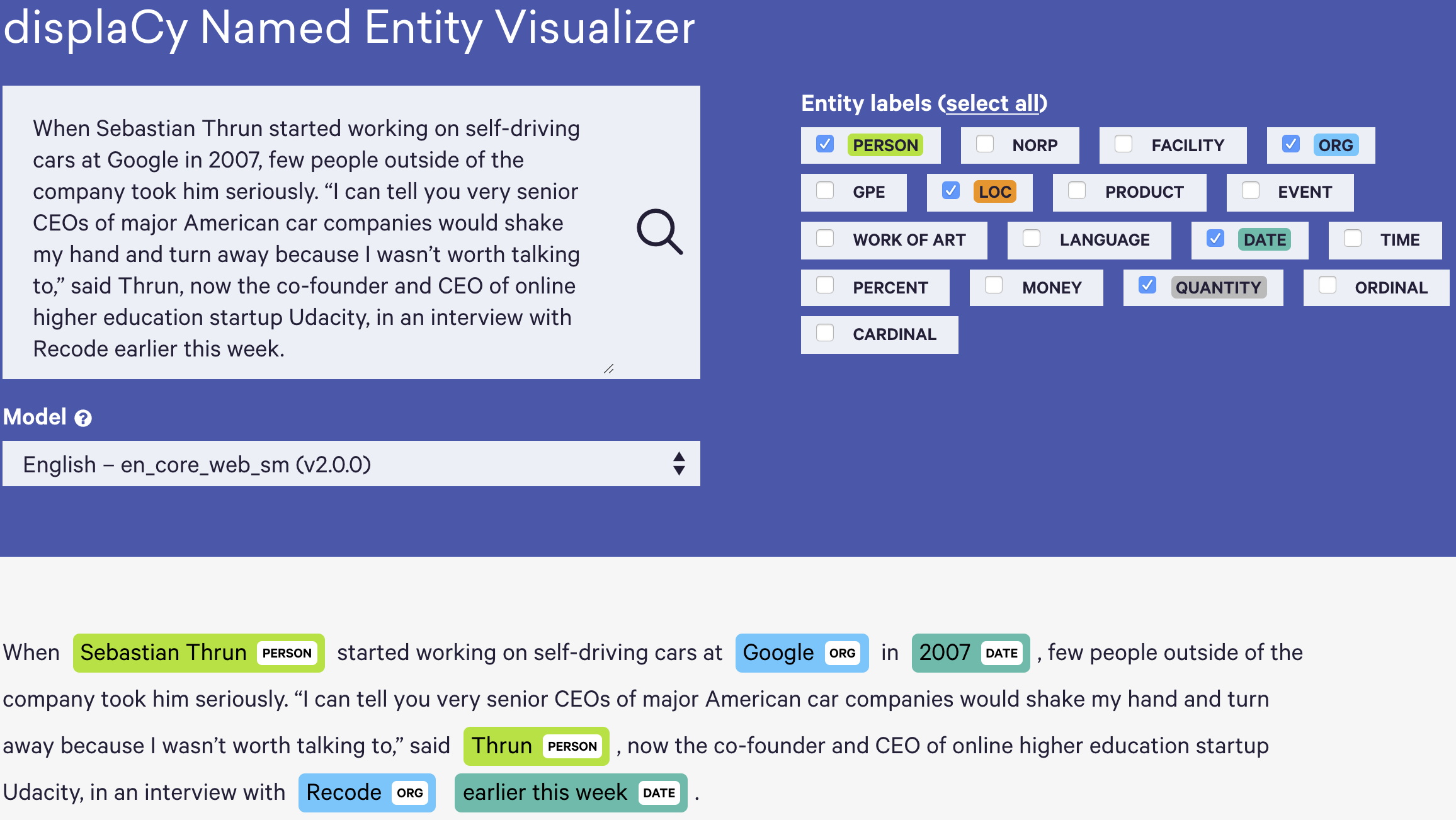
Images from Spacy Named Entity Visualizer
In most applications, the input to the model would be tokenized text. The model output is designed to represent the predicted probability each token belongs a specific entity class.
In the figure above the model attempts to classify person, location, organization and date entities in the input text. Entites often consist of several words.
These models are very useful when combined with sentence classification models. For example, if I were to say “What’s the weather on Sunday?” a sentence classication model could output {category:weather, confidence: 0.976} and an entity recognition model could output {token:Sunday, category:day, confidence:0.99}. Between these two systems, a bunch of engineering work and a large amount of manual response writing, we could build a virtual assistant to respond to textual messages from real live people.
We will use MXNet to train a neural network with convolutional and recurrent components. The result is a model that predicts the entity tag for all tokens in an input sentence. This implementation includes a custom data iterator, custom evaluation metrics and bucketing to efficiently train on variable input sequence lengths.
The model achieves 86.5 F1 points on an 80/20 split of the kaggle named entity recognition dataset, which is really quite good. More on metrics later.
Input Data
The labelling system for named entity recogntion needs to capture information about the position of the entity in the sequence. It also needs to capture whether a token is the start, end or in the middle of an entity. BILOU tagging is used for this:
Minjun (U-person) is (O) from (O) South (B-location) Korea (L-location)
Above, every token is tagged with B,I,L,O or U, followed by the entity label. Minjun (U-person) means the word Minjun is a unit entity of type person. B,I and L refer to beginning, inside and last tags. O means that token is not an entity.
The training data for this post is in the form of a pandas dataframe. The original dataset is from kaggle. The file preprocess.py from my NER github repo will produce the following pandas dataframe:

Note that there are annotation errors in the input data! Entity annotation has to be done by a human :(
Model
Before we can build the model, we need to construct an mxnet iterator to feed mini-batches of data through our neural network. Since our training data is sequences of varying length, we will define a bucketing iterator. This will pad or slice training examples into a predefined list of buckets. MXNet will then create a network graph for each bucket and share parameters between graphs.
The code below defines the BucketNerIter class, which ingests a list of list of indexed tokens, list of list of list of token character indices and a list of list of BILOU tagged entity labels. Input sentences are grouped into batches depending on their length. Each batch has a bucket key. Sentences in the batch are padded/sliced to the bucket size.
class BucketNerIter(DataIter):
"""
This iterator can handle variable length feature/label arrays for MXNet RNN classifiers.
This iterator can ingest 2d list of sentences, 2d list of entities and 3d list of characters.
"""
def __init__(self, sentences, characters, label, max_token_chars, batch_size, buckets=None, data_pad=-1, label_pad = -1, data_names=['sentences', 'characters'],
label_name='seq_label', dtype='float32'):
super(BucketNerIter, self).__init__()
# Create a bucket for every seq length where there are more examples than the batch size
if not buckets:
seq_counts = np.bincount([len(s) for s in sentences])
buckets = [i for i, j in enumerate(seq_counts) if j >= batch_size]
buckets.sort()
print("\nBuckets created: ", buckets)
assert(len(buckets) > 0), "Not enough utterances to create any buckets."
###########
# Sentences
###########
nslice = 0
# Create empty nested lists for storing data that falls into each bucket
self.sentences = [[] for _ in buckets]
for i, sent in enumerate(sentences):
# Find the index of the smallest bucket that is larger than the sentence length
buck_idx = bisect.bisect_left(buckets, len(sent))
if buck_idx == len(buckets): # If the sentence is larger than the largest bucket
buck_idx = buck_idx - 1
nslice += 1
sent = sent[:buckets[buck_idx]] #Slice sentence to largest bucket size
buff = np.full((buckets[buck_idx]), data_pad, dtype=dtype) # Create an array filled with 'data_pad'
buff[:len(sent)] = sent # Fill with actual values
self.sentences[buck_idx].append(buff) # Append array to index = bucket index
self.sentences = [np.asarray(i, dtype=dtype) for i in self.sentences] # Convert to list of array
print("Warning, {0} sentences sliced to largest bucket size.".format(nslice)) if nslice > 0 else None
############
# Characters
############
# Create empty nested lists for storing data that falls into each bucket
self.characters = [[] for _ in buckets]
for i, charsent in enumerate(characters):
# Find the index of the smallest bucket that is larger than the sentence length
buck_idx = bisect.bisect_left(buckets, len(charsent))
if buck_idx == len(buckets): # If the sentence is larger than the largest bucket
buck_idx = buck_idx - 1
charsent = charsent[:buckets[buck_idx]] #Slice sentence to largest bucket size
charsent = [word[:max_token_chars]for word in charsent] # Slice to max length
charsent = [word + [data_pad]*(max_token_chars-len(word)) for word in charsent]# Pad to max length
charsent = np.array(charsent)
buff = np.full((buckets[buck_idx], max_token_chars), data_pad, dtype=dtype)
buff[:charsent.shape[0], :] = charsent # Fill with actual values
self.characters[buck_idx].append(buff) # Append array to index = bucket index
self.characters = [np.asarray(i, dtype=dtype) for i in self.characters] # Convert to list of array
##########
# Entities
##########
# Create empty nested lists for storing data that falls into each bucket
self.label = [[] for _ in buckets]
self.indices = [[] for _ in buckets]
for i, entities in enumerate(label):
# Find the index of the smallest bucket that is larger than the sentence length
buck_idx = bisect.bisect_left(buckets, len(entities))
if buck_idx == len(buckets): # If the sentence is larger than the largest bucket
buck_idx = buck_idx - 1
entities = entities[:buckets[buck_idx]] # Slice sentence to largest bucket size
buff = np.full((buckets[buck_idx]), label_pad, dtype=dtype) # Create an array filled with 'data_pad'
buff[:len(entities)] = entities # Fill with actual values
self.label[buck_idx].append(buff) # Append array to index = bucket index
self.indices[buck_idx].append(i)
self.label = [np.asarray(i, dtype=dtype) for i in self.label] # Convert to list of array
self.indices = [np.asarray(i, dtype=dtype) for i in self.indices] # Convert to list of array
self.data_names = data_names
self.label_name = label_name
self.batch_size = batch_size
self.max_token_chars = max_token_chars
self.buckets = buckets
self.dtype = dtype
self.data_pad = data_pad
self.label_pad = label_pad
self.default_bucket_key = max(buckets)
self.layout = 'NT'
self.provide_data = [DataDesc(name=self.data_names[0], shape=(self.batch_size, self.default_bucket_key), layout=self.layout),
DataDesc(name=self.data_names[1], shape=(self.batch_size, self.default_bucket_key, self.max_token_chars), layout=self.layout)]
self.provide_label=[DataDesc(name=self.label_name, shape=(self.batch_size, self.default_bucket_key), layout=self.layout)]
#create empty list to store batch index values
self.idx = []
#for each bucketarray
for i, buck in enumerate(self.sentences):
#extend the list eg output with batch size 5 and 20 training examples in bucket. [(0,0), (0,5), (0,10), (0,15), (1,0), (1,5), (1,10), (1,15)]
self.idx.extend([(i, j) for j in range(0, len(buck) - batch_size + 1, batch_size)])
self.curr_idx = 0
self.reset()
def reset(self):
"""Resets the iterator to the beginning of the data."""
self.curr_idx = 0
#shuffle data in each bucket
random.shuffle(self.idx)
for i, buck in enumerate(self.sentences):
self.indices[i], self.sentences[i], self.characters[i], self.label[i] = shuffle(self.indices[i],
self.sentences[i],
self.characters[i],
self.label[i])
self.ndindex = []
self.ndsent = []
self.ndchar = []
self.ndlabel = []
#for each bucket of data
for i, buck in enumerate(self.sentences):
#append the lists with an array
self.ndindex.append(ndarray.array(self.indices[i], dtype=self.dtype))
self.ndsent.append(ndarray.array(self.sentences[i], dtype=self.dtype))
self.ndchar.append(ndarray.array(self.characters[i], dtype=self.dtype))
self.ndlabel.append(ndarray.array(self.label[i], dtype=self.dtype))
def next(self):
"""Returns the next batch of data."""
if self.curr_idx == len(self.idx):
raise StopIteration
#i = batches index, j = starting record
i, j = self.idx[self.curr_idx]
self.curr_idx += 1
indices = self.ndindex[i][j:j + self.batch_size]
sentences = self.ndsent[i][j:j + self.batch_size]
characters = self.ndchar[i][j:j + self.batch_size]
label = self.ndlabel[i][j:j + self.batch_size]
return DataBatch([sentences, characters], [label], pad=0, index = indices, bucket_key=self.buckets[i],
provide_data=[DataDesc(name=self.data_names[0], shape=sentences.shape, layout=self.layout),
DataDesc(name=self.data_names[1], shape=characters.shape, layout=self.layout)],
provide_label=[DataDesc(name=self.label_name, shape=label.shape, layout=self.layout)])
Now that we can feed our network, lets talk about its architecture.
Each token in the input sequence has three types of features:
- Tokens are assigned a word embedding feature vector. This could be randomly intialized or some pretrained embedding (word2vec, fastText).
-
Additional word features are generated for each token. These could be categorical features such as whether that word has a capital letter, or some dependancy tag generated from a pretrained machine learning model. The figure below, shows some linguistic features the spacy library can generate. The columns are the features and each row is a token:

Images from Spacy Linguistic Features page
-
Finally, convolutional filters pass over the characters in the token. CNN’s are often used for the task of feature generation in deep learning. Here, the input word is dynamically padded, depending on its length. Each character is assigned a random embedding (which is learned). Each kernel has shape = (w, embedding_vector_size). Max pooling is applied to the 1D kernel output from each filter.

Images from Named Entity Recognition with Bidirectional LSTM-CNNs, Figures 1 & 2
The word embeddings, word features and convolutional character features are concatenated (see figure below). They then pass through the bidirectional recurrent component. Here, an LSTM is unrolled forwards by the length of the input sentence. A second layer is unrolled backwards by the length of the input sentence. This backward layer receives the output from its corresponding unrolled cell in the forward layer, as well as the word feature vector.
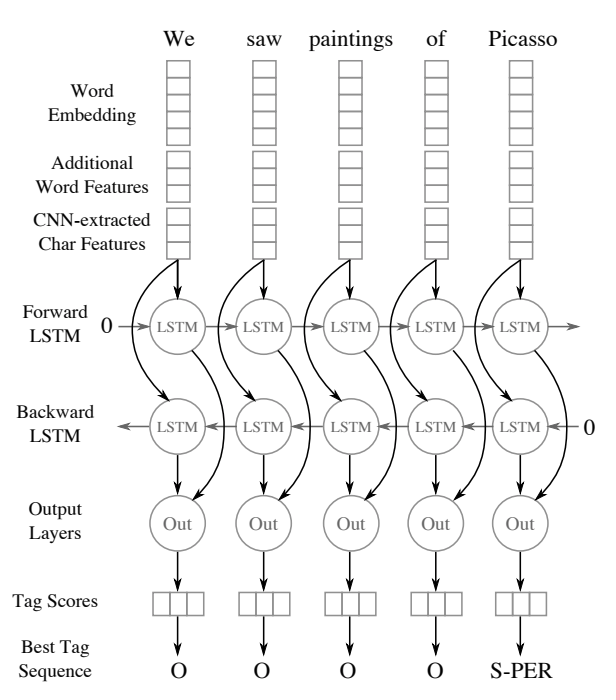
Images from Named Entity Recognition with Bidirectional LSTM-CNNs, Figures 1 & 2
Both forward and backward outputs are combined in the output layer. This layer has number of units = number of possible BILOU entity tags. The log-softmax transformation is used to squeeze the output into the range 0 to 1. The model output can then be interpretted as the predicted probability the input word belows to all possible tags. The output layer for each token is as follows:
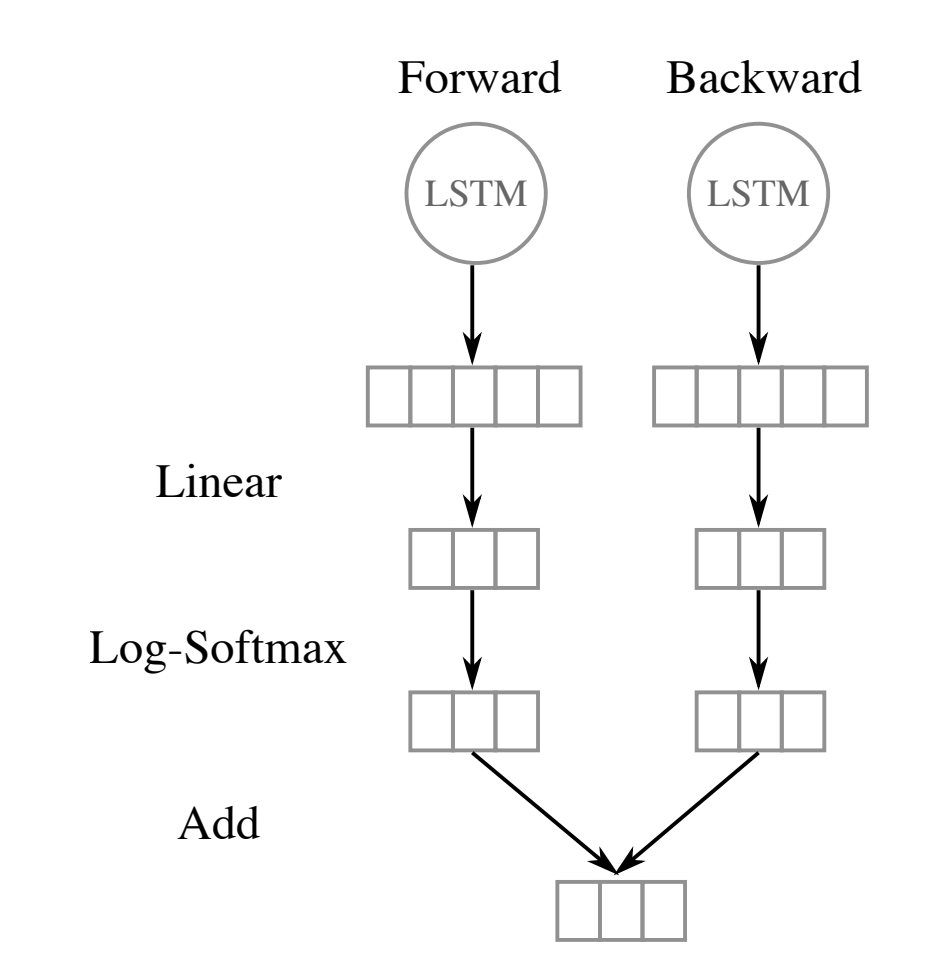
Images from Named Entity Recognition with Bidirectional LSTM-CNNs, Figure 3
The following code constructs a function, which will build a similar network symbol depending on the bucket size of the batch passing through it. Note that this network only encorporates features 1 & 3. My symbol also combines the forward and backward outputs before passing them through a cross entropy loss layer.
def sym_gen(seq_len):
"""
Build NN symbol depending on the length of the input sequence
"""
sentence_shape = train_iter.provide_data[0][1]
char_sentence_shape = train_iter.provide_data[1][1]
entities_shape = train_iter.provide_label[0][1]
X_sent = mx.symbol.Variable(train_iter.provide_data[0].name)
X_char_sent = mx.symbol.Variable(train_iter.provide_data[1].name)
Y = mx.sym.Variable(train_iter.provide_label[0].name)
###############################
# Character embedding component
###############################
char_embeddings = mx.sym.Embedding(data=X_char_sent, input_dim=len(char_to_index), output_dim=args.char_embed, name='char_embed')
char_embeddings = mx.sym.reshape(data=char_embeddings, shape=(0,1,seq_len,-1,args.char_embed), name='char_embed2')
char_cnn_outputs = []
for i, filter_size in enumerate(args.char_filter_list):
# Kernel that slides over entire words resulting in a 1d output
convi = mx.sym.Convolution(data=char_embeddings, kernel=(1, filter_size, args.char_embed), stride=(1, 1, 1),
num_filter=args.char_filters, name="char_conv_layer_" + str(i))
acti = mx.sym.Activation(data=convi, act_type='tanh')
pooli = mx.sym.Pooling(data=acti, pool_type='max', kernel=(1, char_sentence_shape[2] - filter_size + 1, 1),
stride=(1, 1, 1), name="char_pool_layer_" + str(i))
pooli = mx.sym.transpose(mx.sym.Reshape(pooli, shape=(0, 0, 0)), axes=(0, 2, 1), name="cchar_conv_layer_" + str(i))
char_cnn_outputs.append(pooli)
# combine features from all filters & apply dropout
cnn_char_features = mx.sym.Concat(*char_cnn_outputs, dim=2, name="cnn_char_features")
regularized_cnn_char_features = mx.sym.Dropout(data=cnn_char_features, p=args.dropout, mode='training',
name='regularized charCnn features')
##################################
# Combine char and word embeddings
##################################
word_embeddings = mx.sym.Embedding(data=X_sent, input_dim=len(word_to_index), output_dim=args.word_embed, name='word_embed')
rnn_features = mx.sym.Concat(*[word_embeddings, regularized_cnn_char_features], dim=2, name='rnn input')
##############################
# Bidirectional LSTM component
##############################
# unroll the lstm cell in time, merging outputs
bi_cell.reset()
output, states = bi_cell.unroll(length=seq_len, inputs=rnn_features, merge_outputs=True)
# Map to num entity classes
rnn_output = mx.sym.Reshape(output, shape=(-1, args.lstm_state_size * 2), name='r_output')
fc = mx.sym.FullyConnected(data=rnn_output, num_hidden=len(entity_to_index), name='fc_layer')
# reshape back to same shape as loss will be
reshaped_fc = mx.sym.transpose(mx.sym.reshape(fc, shape=(-1, seq_len, len(entity_to_index))), axes=(0, 2, 1))
sm = mx.sym.SoftmaxOutput(data=reshaped_fc, label=Y, ignore_label=-1, use_ignore=True, multi_output=True, name='softmax')
return sm, [v.name for v in train_iter.provide_data], [v.name for v in train_iter.provide_label]
We will use precision, recall and F1 score as performance metrics for this model. That’s pretty standard in entity recognition literature:
- Precision: of the times the model predicts a token is an entity, what percentage were correct?
- Recall: of the training tokens that were entities, what percentage did the model correctly identify?
- F1: 2 x Precision x Recall / (Precision + Recall)
You can find my custom MXNet metric implementations in this script: metrics.py.
Now we simply need to create a trainable MXNet module and fit it to the training data:
def train(train_iter, val_iter):
import metrics
devs = mx.cpu() if args.gpus is None or args.gpus is '' else [mx.gpu(int(i)) for i in args.gpus.split(',')]
module = mx.mod.BucketingModule(sym_gen, train_iter.default_bucket_key, context=devs)
module.fit(train_data=train_iter,
eval_data=val_iter,
eval_metric=metrics.composite_classifier_metrics(),
optimizer=args.optimizer,
optimizer_params={'learning_rate': args.lr },
initializer=mx.initializer.Uniform(0.1),
num_epoch=args.num_epochs,
epoch_end_callback=save_model())
You can find the full training script here: ner.py. This model trained to an F1 score of 86.54 on an Nvidia Tesla K80 GPU in 80 epochs. The hyperparameters were set to the default script values.
The code can be found in my github repo, separated into iterators, metrics and the training script.
Extensions
- The model in the paper minimized the sentence level log-likelihood, not the softmax cross entropy loss.
- The model in the paper limited the possible network output using viterbi decoding. This prevents the model from predicting impossible sequences such as L-location, I-location, B-location.
About the author
Oliver Pringle graduated from the UBC Master of Data Science Program in 2017 and is currently a Data Scientist at Finn.ai working on AI driven conversational assistants.