In this series of blog posts I will outline two highly effective approaches to classifying sentences. This first post will cover a less freqently seen approach…. convolutional neural networks.
Although traditionally used for image processing tasks, CNN’s have proven very effective at various NLP tasks. Lets break down the model, step by step:
Word2vec
Word2vec is an unsupervised learning model, which learns vector representations of words based on the context in which they appear in the input data. Words which appear in similar context (king, queen) will have similar vectors. The length of these vectors is a hyperparameter.
Let’s assume we have 10,000 unique words in our data. This is our corpus. Each input is a one hot encoded word, represented as a vector length 10,000. The vector is zero in all positions, except the position corresponding to the word.
The output layer is also a vector of length 10,000. Each label is a vector, which is 1 in positions corresponding to words which appeared in a given window of the input word. This window size is also a hyperparameter.
 Chris McCormick, (2017), word2vec architecture [ONLINE]. Available at: http://mccormickml.com/assets/word2vec/skip_gram_net_arch.png [Accessed 14 November 2017].
Chris McCormick, (2017), word2vec architecture [ONLINE]. Available at: http://mccormickml.com/assets/word2vec/skip_gram_net_arch.png [Accessed 14 November 2017].
The model consists of a single hidden layer neural network, with linear activation at the neurons. The softmax activation is used at the output layer to ensure model outputs are between 0 and 1.
When trained the model will learn, for a given input word, the probability of any word appearing within a certain window. The intuition is that if two different words have similar words appear around them, they should be considered similar.
Once trained, the weights in the hidden layer can be treated as a numerical representation of each word. Now we can simply build a lookup table, where each word in our corpus is represented by a vector (length 300 in this case). This vector is known as the word embedding.
Representing Language
The input to most language models is not a single word, but a sequence of words. This could be a sentence, paragraph or even an entire book. Both recurrent & convolutional neural network layers allow us to ingest sequences of word embeddings. This is far more effective than averaging the word vectors in each input, since we do not discard any information.
Furthermore, low level deep learning frameworks such as MXNet, Tensorflow & Torch have support for variable length inputs & outputs. This feature is usually referred to as bucketing and reduces the extent to which we must pad or slice the input data.
Convolutional text model
The architecture of the deep (really it’s wide) learning model is as shown below:
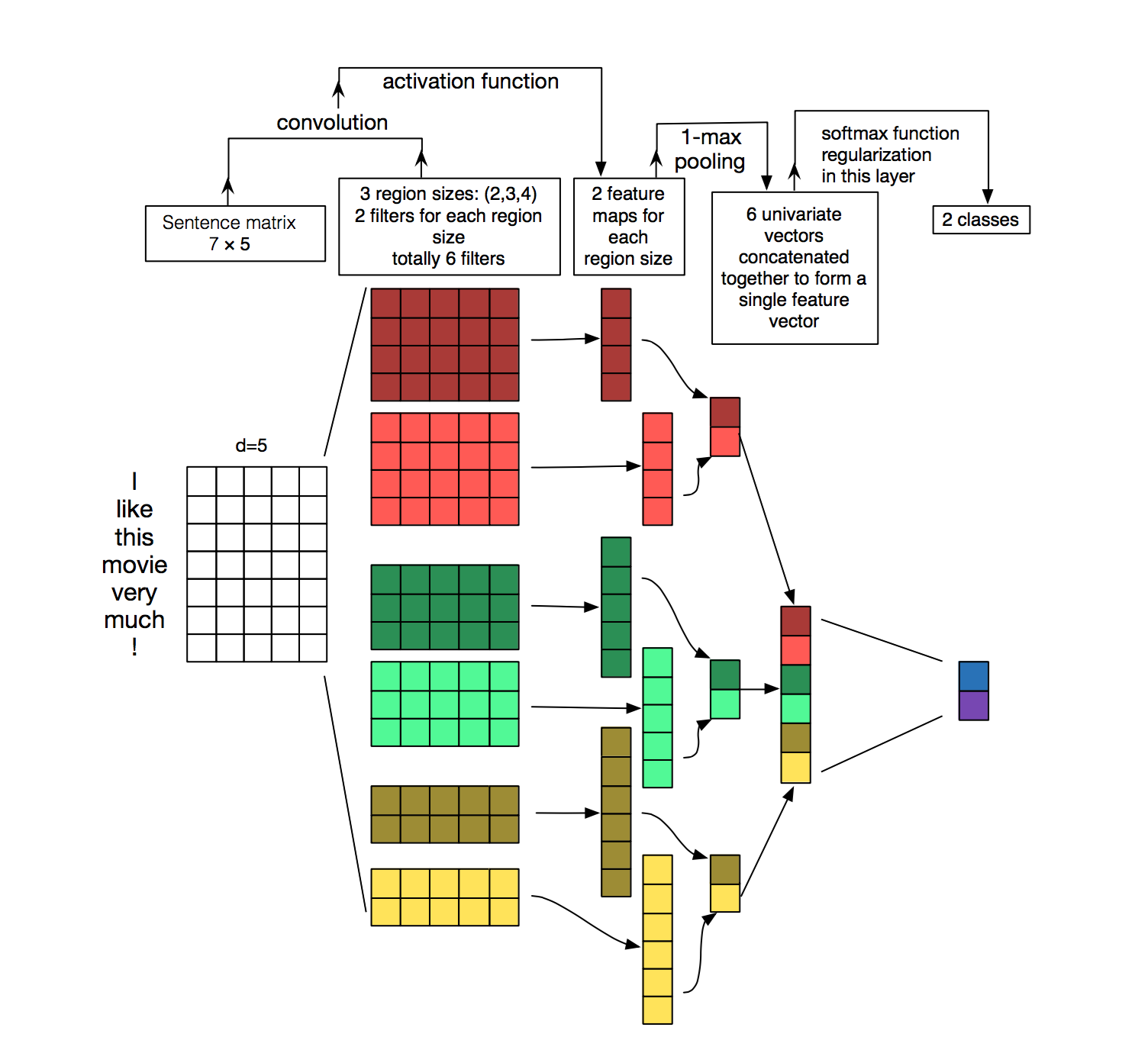 Source: Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification.
Source: Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification.
Input
Each sentence in our data is represented by a matrix of size w by d, where d is the hidden layer size in our word2vec model and w is our prechosen maximum sentence length. The first row of the input example above represents the embedding for the word “I” in our corpus.
Padding is used to ensure our sentences are all the same length (unless we decide to use bucketing). This simply consists of removing words or adding empty words to sentences such that they are all the same length.
Convolutions
The next layer of our network consists of many convolutions of the input. The filters in this model have width = embedding length. The filter slides over the input performing elementwise multiplication.
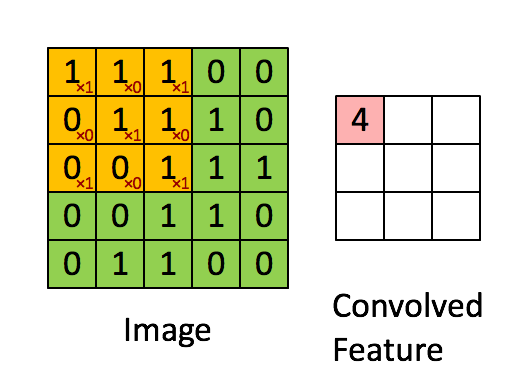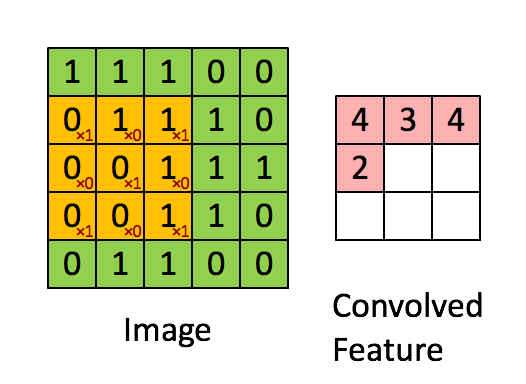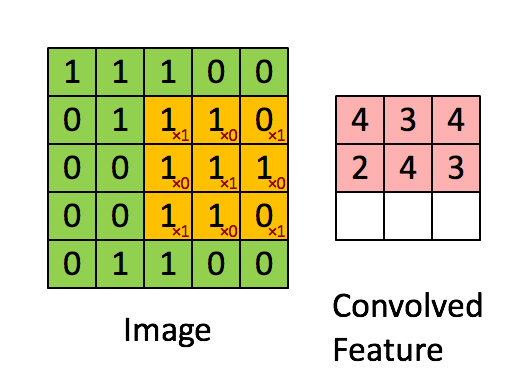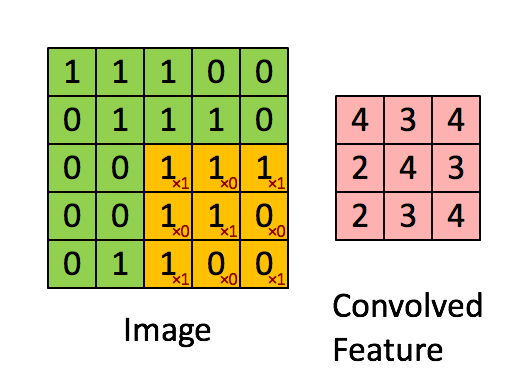
The result is then summed, before applying an activation function to the output.
Pooling and concatenating layer
The maximum value from each filter is taken in the pooling layer. The values from the 6 filters are concatenated into a single vector.
Fully connected layer
This vector is passed to a fully connected layer with size = number of classes we wish to predict to. This layer utilizes the softmax activation, to ensure the output is between 0 and 1. This is useful because we want each neuron to represent the probability that the input sentence belongs to class 0, 1, 2, 3 etc.
Hyperparameters
The following hyperparameters are a good starting point when training this model:
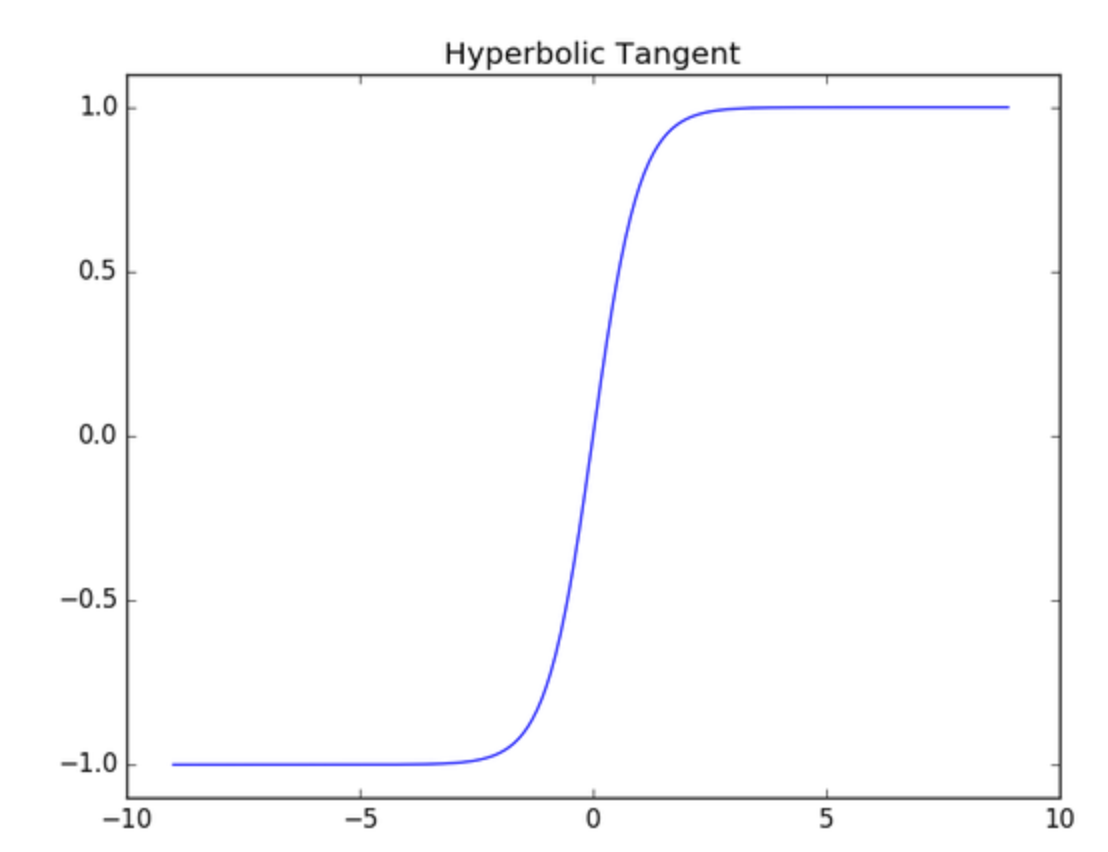
- tanh activation in convolutional layers
- word embedding size 600
- 200 filters of sizes 3,4 and 5
- adam optimizer with learning rate = 0.001
- random weight initialization
Code
See my github for an implementation of this model using Apache MXNet (Amazon’s deep learning framework of choice).
About the author
Oliver Pringle graduated from the UBC Master of Data Science Program in 2017 and is currently a Data Scientist at Finn.ai working on AI driven conversational assistants.